۷ نکته تخصصی برای نوشتن برنامه های امبدد با ChatGPT

امروزه در جهان، از منبع هایی که مدل های هوش مصنوعی مانند ChatGPT دارند پرشده است . منابعی که هوش مصنوعی در متحول کردن کار و سرگرمی مردم دارد خیره کننده و برای برخی کمی ترسناک است. بعنوان مثال، سهام NVIDIA تا به امروز (ژوئن ۲۰۲۳) سه برابر شده است زیرا سرمایه گذاران با انتظارات تقریباً لجام گسیخته بر روی سخت افزار هوش مصنوعی به طور فزایندهای سرمایهگذاری میکنند.
با شروع این تحول،ممکن است توسعهدهندگان سیستم نهفته بپرسند که چگونه میتوانند از هوش مصنوعی به گونه ای بهره برد تا کد بهتر و سریعتری بنویسند. در این پست، ما هفت نکته تخصصی برای نوشتن نرمافزار تعبیهشده با ChatGPT و LLM را بررسی میکنیم که به شما کمک میکند تا کدهایی کارامدتر ، با کمترین خطاهای ایجاد شده توسط هوش مصنوعی را دریافت کنید.
نکته تخصصی شماره ۱ – از آن برای اشکال زدایی کدی که می نویسید استفاده کنید
یکی از فعالیت هایی که من علاقه کمی در توسعه برنامه های تعبیه شده دارم ، عیب یابی هست. در حالی که برخی از توسعه دهندگان عاشق چالش فهمیدن دلیل بودن باگ دریک سیستم هستند، من همیشه گفته جک گانسلز در مورد دیباگ را روشن کننده می یافتم: «اگر یک مرحله عیب یابی وجود داشته باشد، به احتمال زیاد یک مرحله ایجاد خطا وجود داشته است».
توسعه دهندگان سیستم های نهفته قرار نیست دیباگرهای خوبی باشند. قرار است در وهله اول از ورود باگ ها به سیستم جلوگیری کنند! سیستم های امبدد، امروزه سیستم های پیچیده ای هستند و با وجود استفاده از جدیدترین تکنیکها و فرآیندهای موجود، خطاها و رفتارهای غیرمنتظرهای وجود خواهد داشت که توسعهدهندگان باید با آنها کنار بیایند.
به عنوان مثال، من اخیراً یک ضبط کننده ردیابی را در سیستم سفارشی ساخت مشتری یکپارچه کردم. دستورالعملهای یکپارچه کردن سیستم را کاملاً دنبال کردم، متوجه شدم که به دلیل تعاریف متعدد، خطاهای کامپایل دریافت میکنم. ضبط کننده ردیابی به مقداری “linker voodoo” متکی بود تا کتابخانه ردیابی را جایگزین کتابخانه RTOS با نسخه بسته ی recorder-wrapped کند. voodoo کار نمی کرد! با نگاه کردن سریع به فایل ساخته شده، همه چیز خوب به نظر می رسید. عالی! مشخص شد که روز دیباگ کردن نزدیک است.
با نگاهی به خروجی های کامپایلر، متوجه شدم که برخی از ماکرو های توسعه داده شده به درستی کار نمی کنند. به جای انجام فرآیند عیب یابی معمولی، تصمیم گرفتم از ChatGPT با استفاده از دستور زیر بپرسم:

می توانید پاسخ مدل(ChatGBT) را در زیر مشاهده کنید:
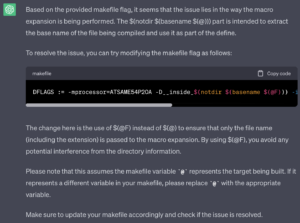
متأسفانه، پاسخ به تغییرات در makefile برای حل مشکل درست نبود. اما با این حال، پاسخ باعث شد فک کنم که شاید تعریف ماکرو توسعه داده شده در جای مناسب قرار نگرفته است. از پاسخ مدل، مشخص شد که برخی از متغیرهای خودکار ممکن است به درستی کار نکنند. چه اتفاقی رخ می دهد اگر به ChatGPT فایل اولیه خود را بدهم و دوباره امتحان کنم؟ پاسخی که دریافت کردم در زیر آمده است:
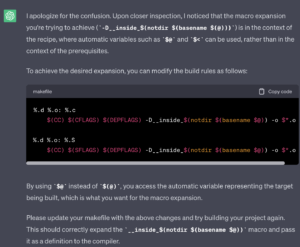
جالبه! همانطور که فکر می کردم، ممکن است مشکلی با متغیر خودکار وجود داشته باشد. علاوه بر این، دستور ساخت نیاز به یک تنظیم جزئی داشت. پس از آزمایش تغییرات پیشنهادی، متوجه شدم که ماکرو توسعه داده شده به درستی کار می کند! من از توصیه دقیق ChatGPT چندان راضی نبودم، بنابراین تنظیمات را دوباره انجام دادم و مطمئن شدم که “خوب به نظر می رسد”.
اگر از ChatGPT برای دیباگ کردن این مشکل استفاده نمیکردم، ممکن بود چندین ساعت فایل makefile بررسی کنم تا بفهمم چه مشکلی وجود دارد. در عوض، من به معنای واقعی کلمه، در کل ۱۰ دقیقه وقت گذاشتم. افزایش مهارت های سریع من برای کار با مدل های هوش مصنوعی منجر به بازدهی بیشتر و سرعت بخشیدن به زمان اختصاص داده شده برای دیباگ شد.
نکته تخصصی شماره ۲ – هدف را به وضوح مشخص و تعریف کنید
شاید در نکته قبلی متوجه شده باشید که اولین تلاش من برای یافتن راه حلی برای مشکلم شکست خورد. زمانی که برای اولین بار با مدل ChatGPT تعامل کردم:
بله، من به وضوح هدف خود را برای حل مشکل تعریف کردم، اما در ابتدا mikefile ام را ارائه ندادم. تنها زمانی که به مدل اطلاعات کافی داده و هدفم را مشخص و واضح بیان کردم، توانست خروجیای را به من ارائه دهد که مشکل من را برطرف کند.
هنگام کار با مدلهای هوش مصنوعی برای توسعه نرمافزار تعبیهشده، بسیار مهم است که هدفتان مشخص و واضح باشد. در حال حاضر، در برخی موارد، این می تواند یک مشکل باشد. اگر سکرت ساس(secret sauce) مخفی شرکت خود را می نویسید، نمی توانید آن را در ChatGPT قرار بدهید، که آن را به عنوان مالکیت عمومی در نظر بگیرد. با این حال، بسیاری از مشکلات نرم افزاری عمومی وجود دارد که می توانید با استفاده از یک مدل هوش مصنوعی کد خود را حل کرده و بنویسید.
هرچه اطلاعات بیشتری در اختیار مدل قرار دهید، نتایج بهتری خواهید داشت. به عنوان مثال، اگر به مدل هوش مصنوعی بگویید “من باید به یک سنسور وصل شوم”، این خیلی مشخص نیست و مدل نمی داند به چه چیزی نیاز دارید. فقط برای سرگرمی، این را از ChatGPT پرسیدم، و این پاسخی است که دریافت کردم:

اگر بخواهید از یک رویکرد تکراری استفاده کنید، که به زودی در مورد آن صحبت خواهیم کرد، این رویکرد می تواند خوب باشد، اما شما را به نتیجه دلخواهتان نمی رساند. با این حال، اگر آن درخواست را به صورت زیر بیان کنید:
من باید برای یک سیستم امبدد که با یک سنسور دمای TMP36 با استفاده از پروتکل I2C ارتباط برقرار می کند، یک تابع به زبان C بنویسم که این تابع باید اتصال به سنسور را آغاز کند، داده های دما را هر ۵ ثانیه بخواند، داده های خام را به سانتیگراد تبدیل کند و مقدار دما را برگرداند. همچنین، این فانکشن باید شامل رسیدگی به خطا برای سناریوهایی باشد که سنسور پاسخ نمی دهد.
مدل ChatGPT در اولین تلاش چیزی بسیار نزدیک به آنچه می خواهم ارائه می دهد:
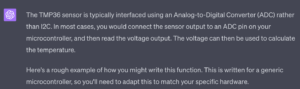
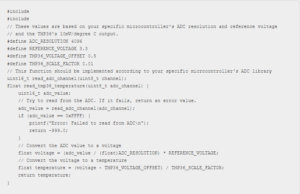

من نه تنها مقداری کد نمونه دریافت می کنم، بلکه توضیحی در مورد کد و جاهایی که ممکن است بر اساس احتیاجات خود ،نیاز به اصلاح داشته باشم نیز دریافت می کنم. عالی نیست، اما بد هم نیست!
نکته تخصصی شماره ۳ – مدیریت خطا را در نظر بگیرید
من بیش از ۲۰ سال است که با سیستم های نهفته کار می کنم و بیش از نیمی از این مدت را مشاوره می دهم.یک بخشی وجود دارد که من هر بار می بینم که تیم ها و توسعه دهندگان در آن کوتاهی می کنند و آن رسیدگی به خطا ها است.
من کدهای زیادی را می بینم که در آن مقادیر بازگشتی نادیده گرفته می شوند و خطاها ممکن است بیداد کنند زیرا هیچ کس نمی داند که چه چیز در حال رخ دادن هست. اکثر کدها با این فرض نوشته می شوند که همه چیز درست خواهد بود. من خوش بینی را دوست دارم، اما در این مورد نه.
اگر کدی را با استفاده از یک مدل هوش مصنوعی مانند ChatGPT می نویسید، میتوانید از مدل بخواهید که مدیریت خطا ها را نیز لحاظ کند. در واقع، من فقط این کار را در آخرین نکته ، زمانی که درخواست خاص خود را نوشتم، انجام دادم. مدیریت خطا یک بخش مهم برای نوشتن firmware قوی است. به جای نادیده گرفتن آن، از هوش مصنوعی بخواهید به خطا های کدتان رسیدگی کند. این نرمافزار شما را قویتر میکند و نیازی به صرف زمان زیادی به جز بررسی سریع کد نخواهید داشت.
نکته تخصصی شماره ۴- از تعاملات تکراری استفاده کنید
در نکته قبلی، اشاره کردم که شما باید برای به دست آوردن خروجی مطلوب ، هدف خود را مشخص کنید. گاهی اوقات، ممکن است ندانید چه می خواهید، یا ایده ای دارید، اما ندانید که برای رسیدن به خروجی مطلوب باید چه سوالی را مطرح کنید. هنگامی که این اتفاق می افتد، می توانید از تعاملات تکراری برای یافتن کدی که می خواهید بنویسید استفاده کنید.
تعاملات تکراری با یک مدل هوش مصنوعی میتواند با یک ایده یا نیاز کلی شروع شود و سپس، از طریق تعاملات متعدد با مدل، به آرامی به یک نتیجه دقیقتر و کاملتر رسید. به عنوان مثال، در یک پست وبلاگ اخیر با عنوان “رویکرد تکراری برای طراحی USART HAL با استفاده از ChatGPT “من از این رویکرد برای توسعه یک USART HAL استفاده کردم.
درخواستهای اولیه من به مدل هوش مصنوعی سهولت زیادی برای ایجاد یک رابط پیشنویس میداد، اما درخواستهای بعدی تا زمانی که به نتیجه مطلوب برسم، بهبودهای تدریجی را ارائه می داد. من نیازی به توضیح کامل جزئیات از قبل نداشتم، هر چند اگر می دانستم دقیقاً چه می خواهم، می توانستم امتحان کنم.
نکته تخصصی شماره ۵ – توضیحات کد را بخواهید
در مقطعی از حرفه ی هر توسعهدهندهای، با کدهایی مواجه میشوید که نمیفهمید. شاید شما شروع به یادگیری یک زبان جدید کرده اید یا برخی از توسعه دهندگان فکر می کنند که باهوش هستند و چیزی نوشته اند که فقط خودشان می توانند بفهمند. وقتی این موارد پیش میآید، یک مدل هوش مصنوعی میتواند به شما کمک کند تا بررسی کنید که درک شما از کد در واقع درست است یا نه.
به عنوان مثال، فرض کنید شما یک توسعه دهنده C سطح ابتدایی هستید و با برنامه ای مواجه می شوید که برای اولین بار از نشانگرهای تابع استفاده می کند. یک برنامه ساده مانند زیر:
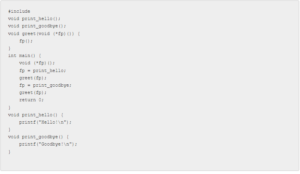
اگر نمیدانستید کد یا برنامه در حال انجام چه کاری است، آن را در برنامهای مانند ChatGPT قرار دهید و بپرسید: «کد زیر چه کاری انجام میدهد؟»
وقتی این را در ChatGPT قرار می دهم، نتایج زیر را دریافت می کنم:

مطمئناً میتوانم سؤالات بعدی را بپرسم تا زمانی که نرمافزار را متوجه شوم.
نکته تخصصی شماره ۶ – بررسی کدها را انجام دهید
بررسی کد یک فرآیند ضروری است که هر تیم برنامه های امبدد باید از آن استفاده کند. با این حال، اغلب متوجه شدهام که تیمها در انجام بازبینی کد نظم چندانی ندارند. فشارهای کاری اغلب باعث می شود آنها از بررسی ها صرف نظر کنند و از کد در اسرع وقت خروجی بگیرند. یکی از کاربردهای جالب مدلهای هوش مصنوعی، بررسی کدها است. بیایید مثال کد نکته ی قبلی را دوباره از طریق ChatGPT اجرا کنیم، اما این بار، از آن میخواهیم کد را بررسی کند و توصیههایی را برای بهبود در اختیار ما قرار دهد.
نتایجی که به دست آوردم در زیر قابل مشاهده است:

همه اینها خوب هستند، با توجه به اینکه برنامه ساده ای را برای شروع انتخاب کردیم، به نظر من جالب است که وقتی از ChatGPT میخواهیم کد را بررسی کند، نه تنها آن را بررسی میکند، بلکه نسخه جدیدی از کد را با اعمال این تغییرات ایجاد میکند. در زیر می توانید نسخه به روز شده را مشاهده کنید:

معمولاً یک توسعهدهنده باید تغییرات توصیهشده را انجام دهد و به عقب برگردد و کد خود را بازنویسی کند. در این حالت، بروز رسانی ها به طور خودکار ایجاد می شوند.
نکته تخصصی شماره ۷ – به خروجی اعتماد نکنید
آخرین نکته تخصصی که امروز می توانم برای نوشتن برنامه های امبدد با ChatGPT به شما بگویم این است که به آن اعتماد نکنید. میدانم که با توجه به اینکه ChatGPT میتواند برای نوشتن نرمافزار مفید باشد، به نظر غیرشهودی برسد. اما این بدان معنا نیست که شما باید کورکورانه به آن اعتماد کنید. شما باید به دقت کدی را که تولید میکند را بررسی کنید تا از عملکرد کد، آنطور که انتظار دارید اطمینان حاصل کنید.
از مدلهای هوش مصنوعی برای این اهداف و از روشهایی که در مورد آن صحبت کردیم استفاده کنید، اما مطمئن شوید که خروجی را به دقت بررسی کرده و آن را آزمایش کردهاید. هنگامی که شما شروع به اعتماد بیش از حد به آن کنید، در آن زمان است که با یک مشکل واقعی روبرو خواهید شد.
همیشه بررسی کنید که خروجی منطقی باشد. این مدل ها فقط مدل های آماری هستند که توکن بسیار محتمل بعدی را در یک دنباله تولید می کنند. این احتمال وجود دارد که مدل های امروزی برای نوشتن کدهای با قابلیت اطمینان بالا آموزش ندیده باشند. اما اشتباه نکنید، میتوانید از این تکنیکها برای نوشتن یک نرمافزار تعبیهشده عالی، استفاده کنید، هرچند که از خروجی مدل راضی نباشید.
نتیجه گیری
آخرین پیشرفت ها در مدل زبانی بزرگ، هوش مصنوعی را قادر به تولید کد، به ویژه سیستم های امبدد، کرده است. در این پست، نکات تخصصی برای تعامل با مدلهای هوش مصنوعی برای نوشتن نرمافزار تعبیهشده را بررسی کردهایم. نتایجی که می توانید به دست آورید می تواند بسیار مفید باشد. شما می توانید زمان و هزینه های توسعه را کاهش دهید، اما باید در مورد نحوه تعامل خود با مدل ها بسیار مراقب باشید. شما نباید اطلاعات یا کد اختصاصی را به مدل ارسال کنید. همچنین نمی توانید کورکورانه به خروجی مدل ها اعتماد کنید.
ظهور LLM ها به طرز چشمگیری بر نحوه طراحی سیستم های نهفته در آینده تأثیر می گذارد. آن آینده ممکن است هنوز اینجا نباشد، اما ممکن است بسیار نزدیکتر از آن چیزی باشد که شما تصور می کنید.